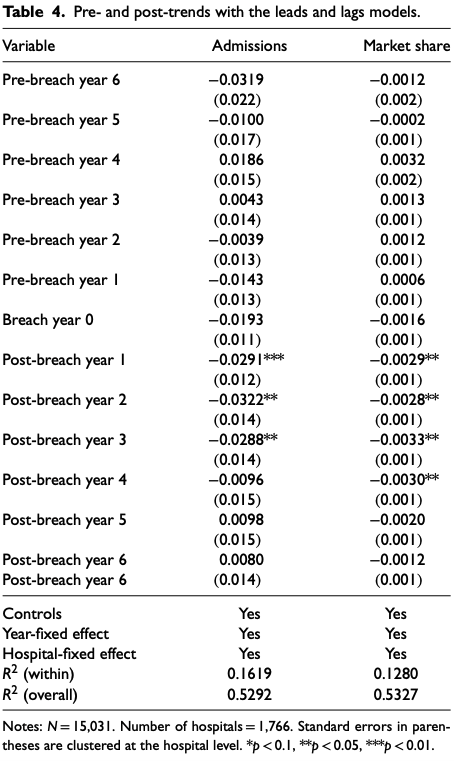
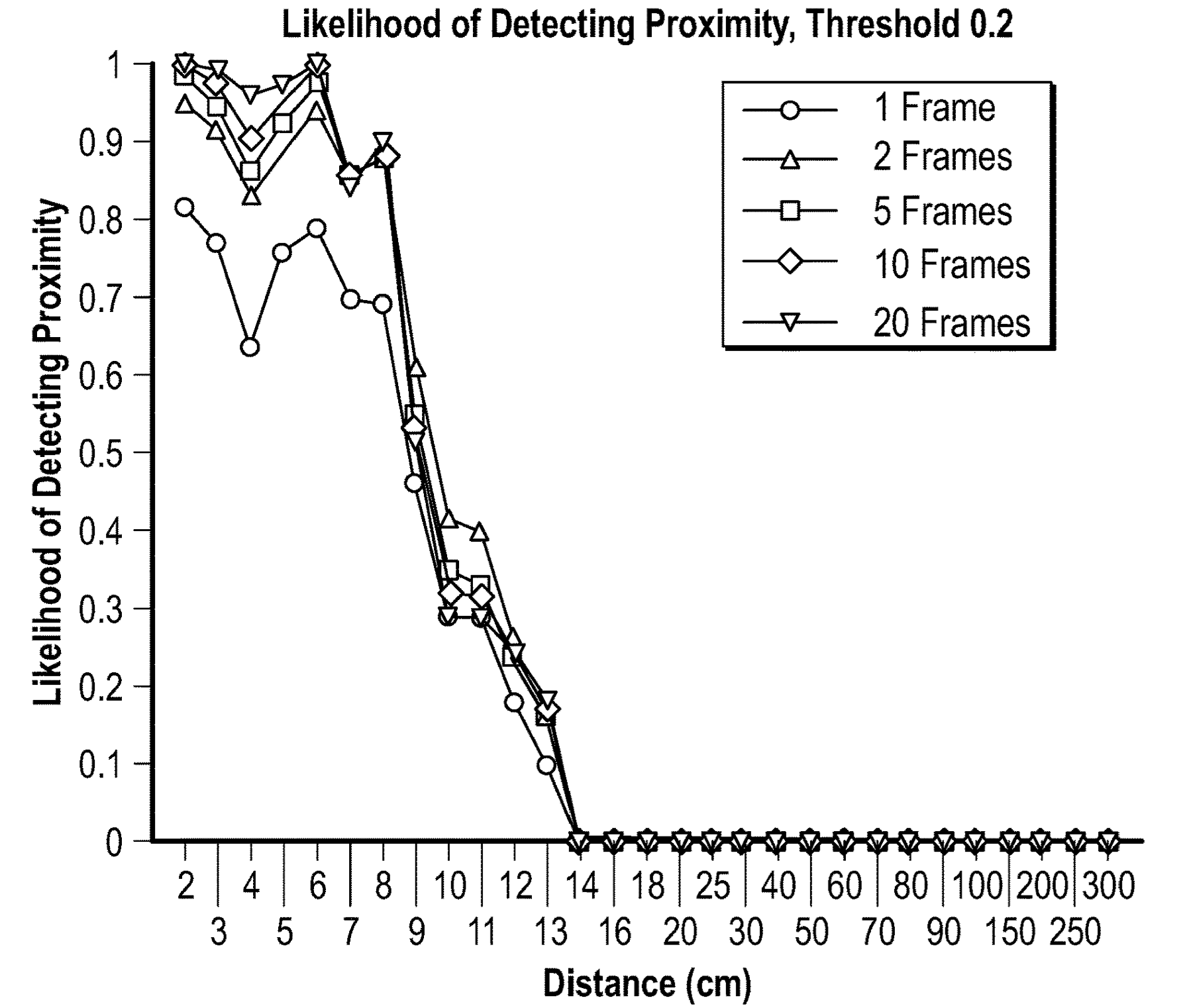
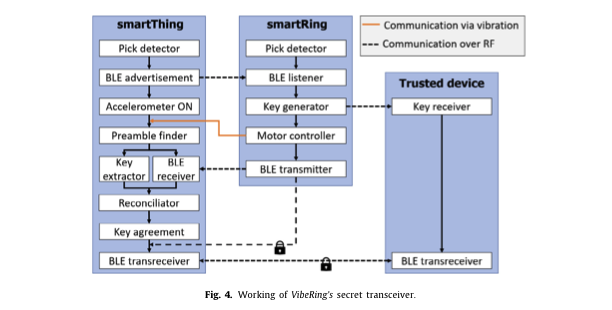
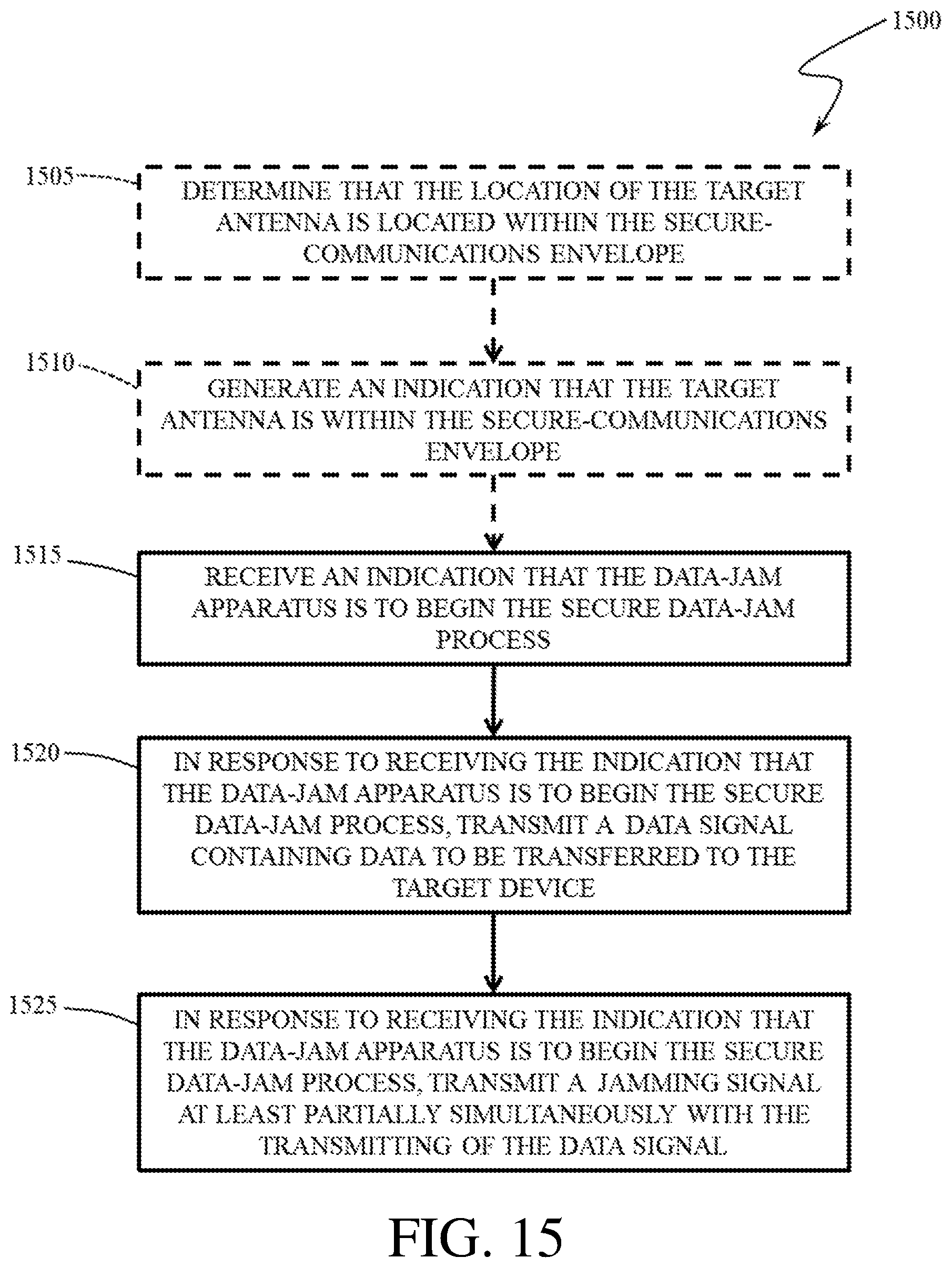
In 2013, the National Science Foundation’s Secure and Trustworthy Cyberspace program awarded a Frontier grant to a consortium of four institutions — Dartmouth College, the University of Michigan, the University of Illinois Urbana-Champaign, and Johns Hopkins University — to enable trustworthy cybersystems for health and wellness. Over the years, THaW grew to include researchers from Vanderbilt University, Morgan State University, and George Washington University.
Over 80 students and postdocs engaged in THaW research activities over the span of the project, and the project’s bibliography includes more than 130 significant publications. You can find an organized overview of these publications here. The THaW team devised systems and methods to enhance security, resulting in 11 patents. Team members were featured in various news outlets, and THaW PI Kevin Fu co-founded VirtaLabs to identify, assess, patch, and track clinical assets in health care environments.
THaW collaborated with The Archimedes Center for Medical Device Security in Michigan to offer a twice-annual training conference on how to integrate THaW security principles into the design of medical devices to clinical engineers and CISOs from hospitals and medical device manufacturers. Over 10,000 people and more than 100 industry organizations attended the events. In addition, Archimedes conducted on-site security training for more than 500 medical device engineers over the years.
If you are interested in taking advantage of any of the resources within this site, the contact us page of this website will remain active. The rest of the website will no longer be updated. Thank you to those of you who have followed this site and the THaW project over the past 11 years.